One of the five architectures below describes the tensions your team is living with right now. If none of them do, your current design is still earning its keep. Don't fix what isn't broken. Most applications start here, and many should stay. One database handles all reads and writes. Application-tier caching absorbs read load. One source of truth. One operational surface. Simple, not primitive. Internal tools, bounded-domain services, and applications with predictable data volumes don't need distribution. Adding it would be an unforced error. What teams typically do: Add a caching layer. Move the hot 20% of data into an in-memory cache. Cache-aside drops read latency and offloads the database from 100% of read traffic to the percentage that misses cache. SLAs met, database CPU drops, customers stop complaining. What caching introduces: A second platform that must stay synchronized with the first. The database is the source of truth. The cache is a copy. Keeping them synchronized is the hard part. The search team adds Elasticsearch. The analytics team adds a warehouse. The session layer moves to a dedicated store. Each decision makes sense in isolation. Before long, what was one database is five systems, each optimized for a different access pattern. Adding the cache was the first step. Search, analytics, and event streaming made three, four, five. What teams typically do: Shard the database. Cluster the cache. Each platform becomes a cluster of nodes. Horizontal scaling replaces the synchronization ceiling with capacity to handle enterprise-scale volume. What distribution introduces: Data scattered across nodes. Operations that were local become distributed. Capacity increases, but the latency profile changes in ways that aren't obvious until peak load. Everything is a cluster now. The relational database is sharded. The cache runs as a distributed grid. The document store spans regions. No single node holds all the data. Before distribution, one query hit one database. After distribution, the same logical operation requires network coordination across multiple systems, and the slowest one determines the response time. What teams typically do: Build a transaction coordinator. Separate read and write paths. Bridge the gap with cache-store integration: write-through for critical data, write-behind for everything else. What orchestration introduces: The coordination layer itself becomes a system with its own failure modes. When it works, the design delivers both speed and consistency. When it fails, the failure mode is worse than what it was built to prevent. If you drew your architecture on a whiteboard right now, the arrows would outnumber the boxes. The transaction coordinator manages the boundary between consistency and scale. Event logs, separated read/write paths, and cache invalidation rules fill in around it. Strong consistency for critical paths. Eventual consistency for everything else. What teams typically do: Look for platforms that solve consistency at the data layer rather than the coordination layer. If the data platform keeps related data together and provides ACID guarantees internally, the coordination that bridges cache, database, and transaction coordinator becomes unnecessary. The schema declares which data belongs together, and the platform enforces it. Consensus provides strong consistency without distributed locks. Memory-first storage delivers microsecond access within transaction boundaries. The separation between "cache for speed" and "database for consistency" narrows because the data platform provides both. The complexity shifts from operations to design. Data placement decisions (which tables share a partition key, which are replicated, how partition keys align with transaction boundaries) directly affect whether transactions execute locally or require cross-partition coordination. A bad schema reintroduces the coordination overhead the design was meant to eliminate. Most teams overestimate where they are. A common pattern: the team believes they're distributed, scaling horizontally, but the actual tension is a multi-system synchronization problem. Treating a synchronization problem with more distribution makes it worse. Before changing anything, confirm what the indicators are telling you. Two learning paths, matched to where your architecture is today. Each leads to hands-on tutorials with working code you can run on your laptop.A Single System
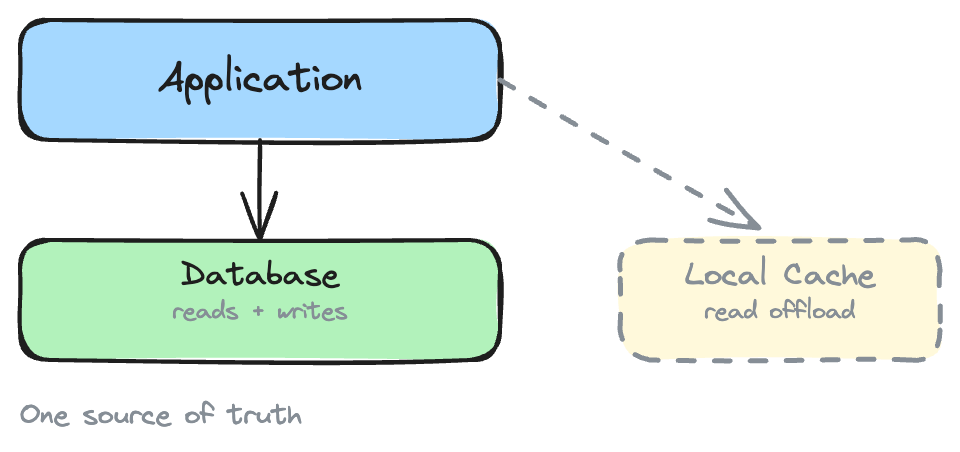
You start feeling the limits when
Specialized Persistence
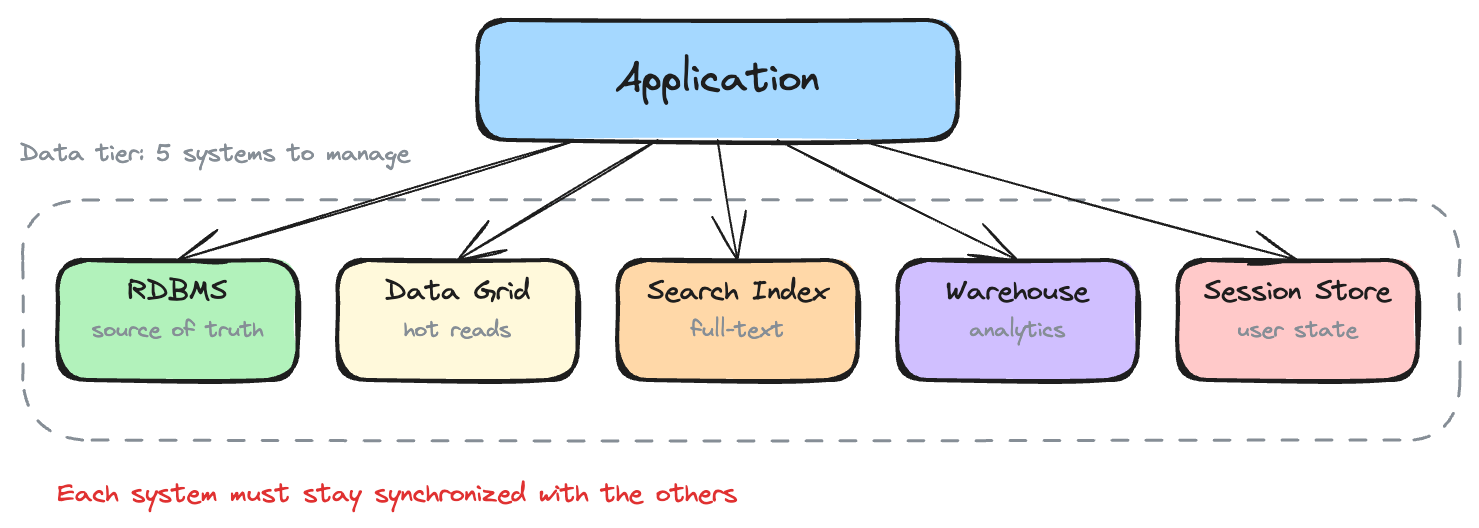
You start feeling the limits when
Distributed by Default
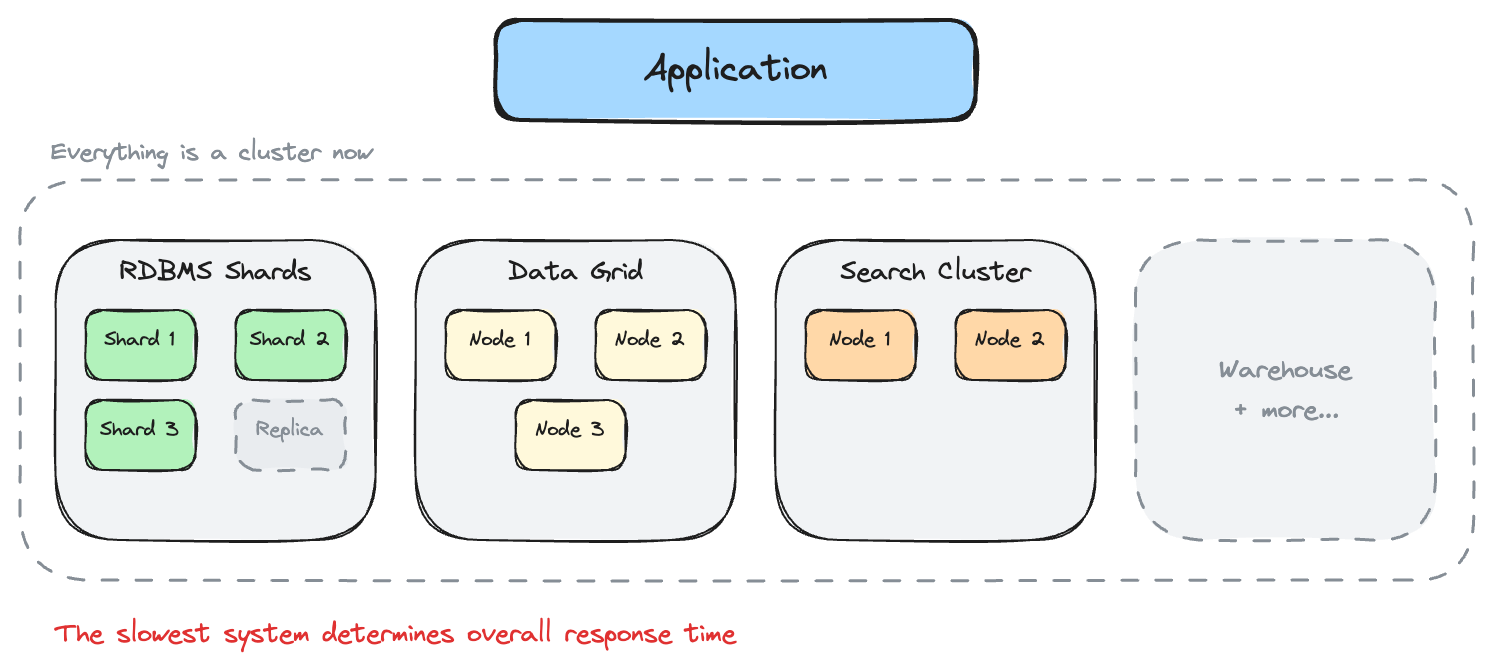
You start feeling the limits when
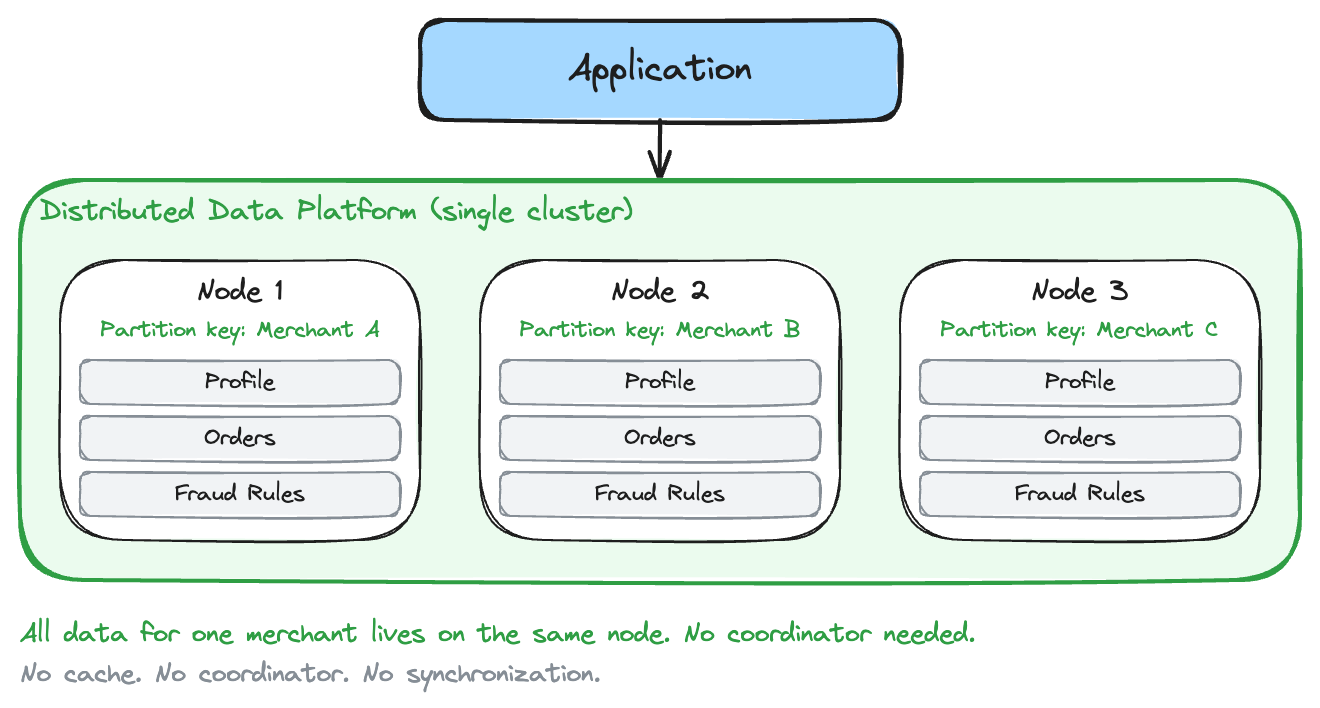
Managed Consistency
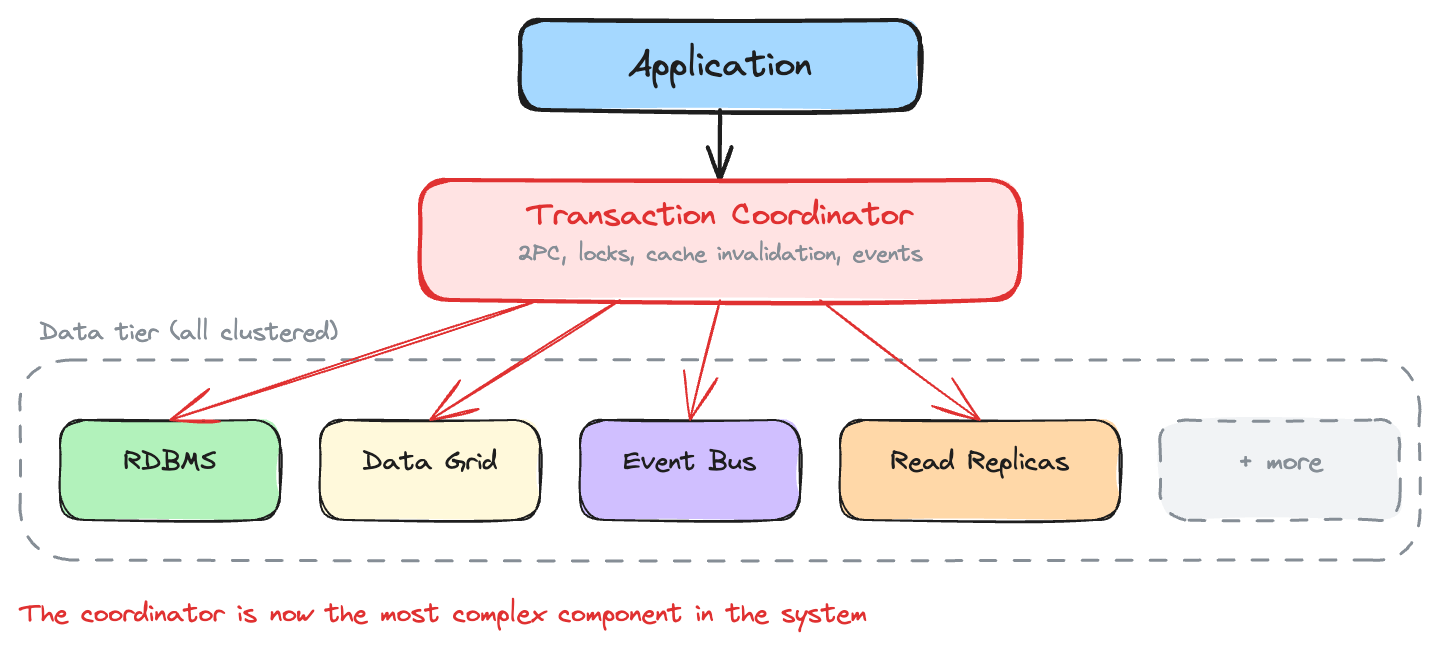
You start feeling the limits when
Acceleration Database
What this provides
Putting This to Work
Three questions that narrow the solution space
Transition Assumption that's outgrown What replaces it Single System to Specialized Persistence One system handles everything Each workload needs its own optimized system Specialized Persistence to Distributed Independent systems stay synchronized Data must be distributed; consistency becomes secondary Distributed to Managed Consistency Distribution handles consistency Consistency must be explicitly managed across distributed data Managed Consistency to Acceleration Database Consistency can be orchestrated on top of distribution Consistency built into the storage layer through data placement and consensus Ready to start building?
When Your Data Architecture Is Ready, Evolve
The decisions that got you here won't get you to the next stage. Every scaling strategy solves one class of problems and creates the conditions for the next challenge.
1
2
3
4
5